Buckets¶
Getting Started¶
If you're familiar with cloud storage, you'll find buckets easy to understand.
However, unlike traditional cloud services, buckets are built on open, decentralized protocols including the IPFS and Libp2p. You can serve websites, data, and apps from buckets.
Buckets are packed with useful features:
- Explore your Buckets on the Hub gateway.
- Render web content in your Bucket on a persistent website.
- Automatically distribute your updates on IPFS using IPNS.
- Collaboratively manage Buckets as an organization.
- Create private Buckets where your app users can store data.
- (Soon) Archive Bucket data on Filecoin to ensure long-term security and access to your files.
Initialize a Bucket¶
To start a Bucket in your current working directory, you must first initialize it. You can initialize a bucket with an existing UnixFS DAG, available in the IPFS network, or import it interactively in an existing bucket.
When working on your local machine, buckets are mapped to working directories.
Once you initialize a bucket in a directory, anytime you return to the directory, the Textile CLI will automatically detect the Bucket you're interacting with.
Info
Bucket names are unique to a developer and within an Org. They're not globally unique.
Warning
Be careful about creating a bucket in a root directory because all children directories become linked to that bucket. To move or remove a bucket's link to a directory, edit, move or delete the .textile/config.yml file (it will be a hidden folder in the bucket's directory)
Shared buckets¶
You can create buckets to share with all members of an organization.
To do so, simply initialize an Org first and then initialize a Bucket using the HUB_ORG environmental flag, by specifying the name of the Org you want to share the bucket with.
For example, HUB_ORG=astronauts hub bucket init.
All members of the Org will be able to push and pull files to and from the shared Bucket. Read more about creating Orgs.
Info
To check which org a bucket is registered with, examine the .textile/config.yml file (it will be a hidden folder in the bucket's directory).
Encrypted buckets¶
It's possible to create encrypted buckets.
The contents of encrypted buckets will still exist on IPFS but the contents will be obfuscated to any viewer that doesn't have access to the encryption keys.
You can choose to create encrypted buckets when creating them in the CLI or when initializing them in the JavaScript library.
Publishing content¶
Push new files¶
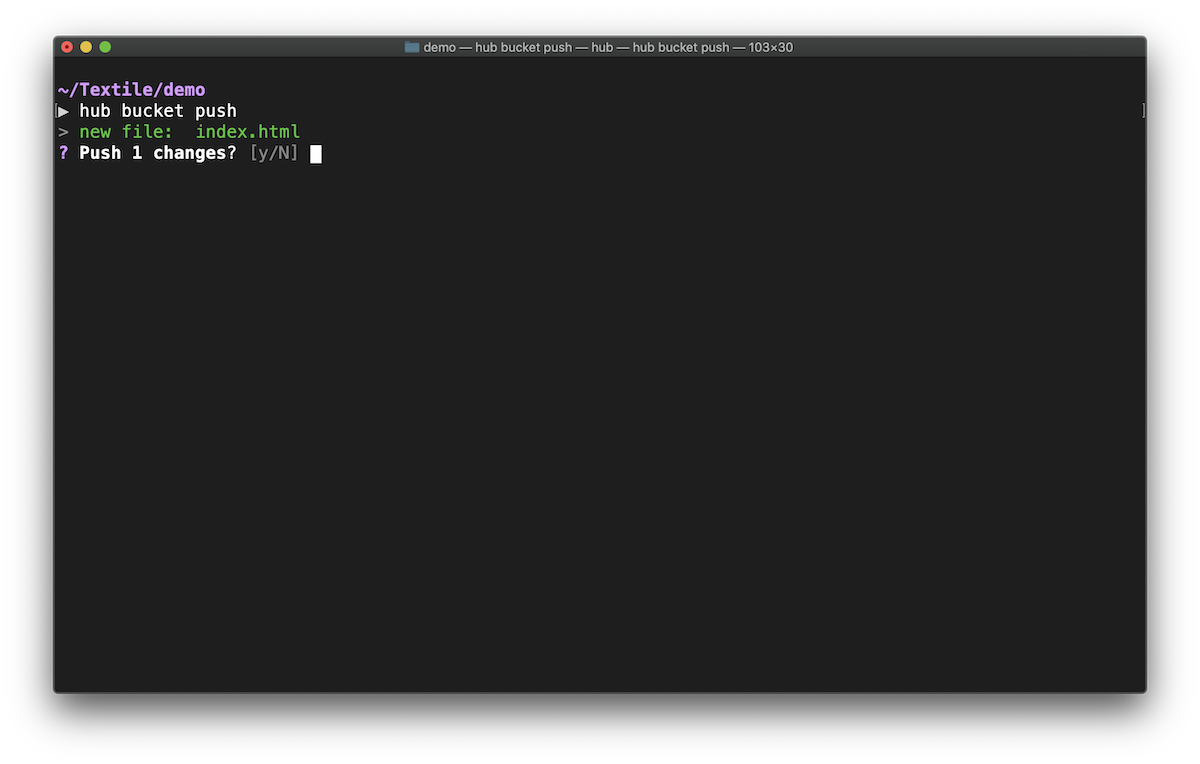
hub bucket push
Diffing and Syncing¶
When a bucket is pushed to the remote API (the Hub):
- Its Merkle DAG representation is saved locally as a reference of the latest pushed version.
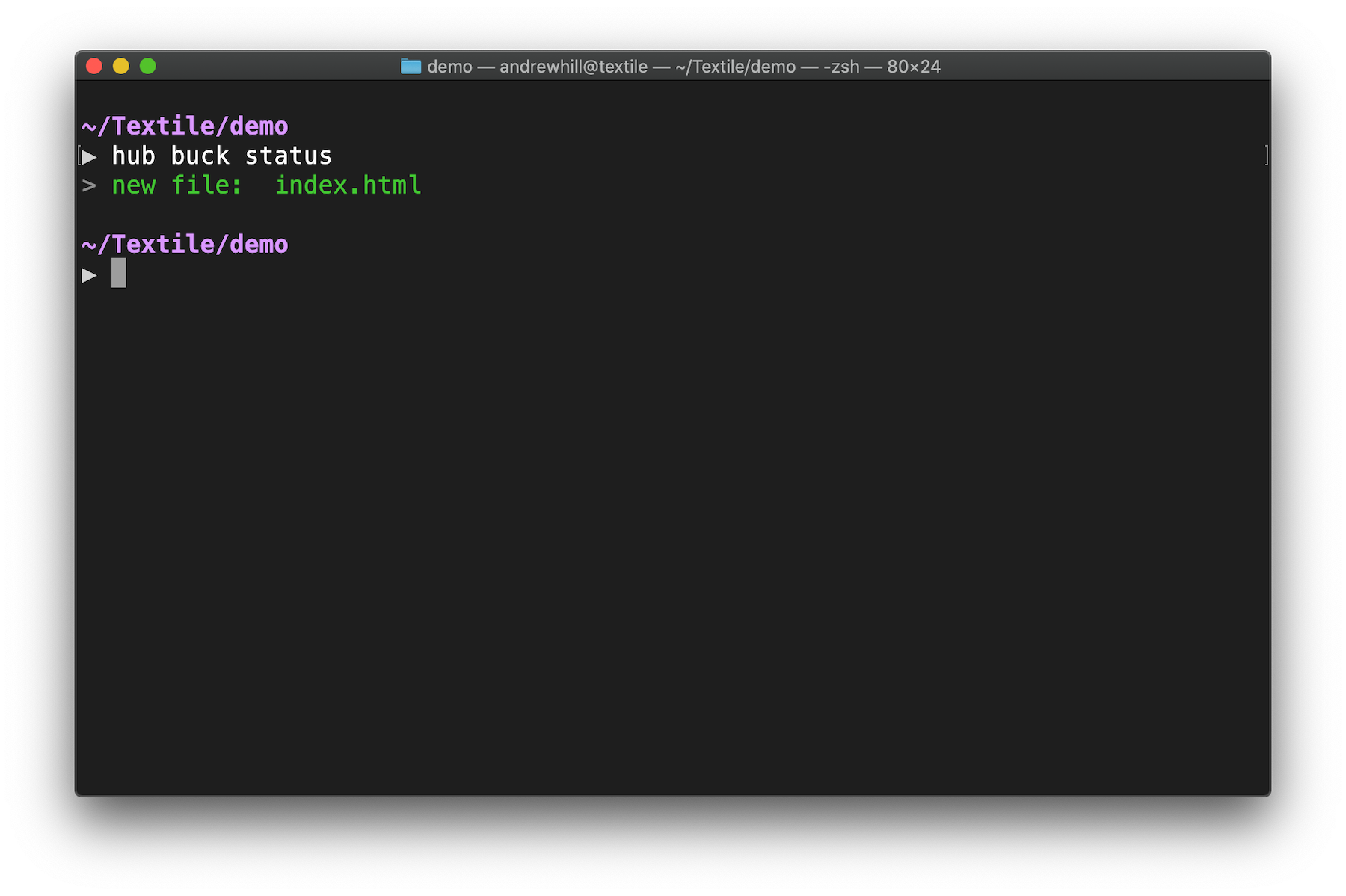
- When you execute
hub buck status, it compares the persisted Merkle DAG with a generated Merkle DAG of the Bucket local state. - Walking both DAGs and comparing CIDs can quickly provide paths that changed to the last known version.
In a nutshell, when a bucket is pushed, the persisted Merkle DAG contains the minimum amount of information about the directory structure and data fingerprints. Read more about this process.
Encryption¶
You can encrypt bucket contents by opting-in to the option when you create your bucket.
The encryption setup is based on AES-CTR + AES-512 HMAC as seen here. This is a modified version of the encryption library Google Drive uses to handle large streams (files).
Encrypted buckets have a couple of goals:
- Obfuscate bucket data/files (the normal goal of encryption).
- Obfuscate directory structure, which means encrypting IPLD nodes and their links.
The AES and HMAC keys used for bucket encryption are stored in the ThreadDB collection instance. That means each bucket has a model entry as a key.
This setup allows for bucket access to be inherited by thread ACL rules. This also means that if you can break into the thread, and you gain access to the thread read key, you can decrypt the bucket content.
As a compromise, we've added some convenience methods to the local buck client which allows you to encrypt content locally (protected by a password) before it gets added to the bucket. This has the downside that you must remember the password.
Finally, you can run the standalone buckets daemon buckd locally and use a remote peer as a thread replicator (no read key access). This means that there’s no downside to the keys being stored in the bucket collection instance.
Password-based encryption uses the same approach but also leverages scrypt to derive the keys from the password.
This carries the normal tradeoff: The encryption is only as good as the password.
Retrieving content¶
Pull files¶
hub bucket init --existing
Info
Use the --existing flag to list buckets already pushed by you. Use HUB_ORG to list buckets already pushed by your collaborators.
Explore on the gateway¶
To inspect your pushed files, explore on the gateway:
hub bucket links
then open the first result 'Thread links' in your browser.
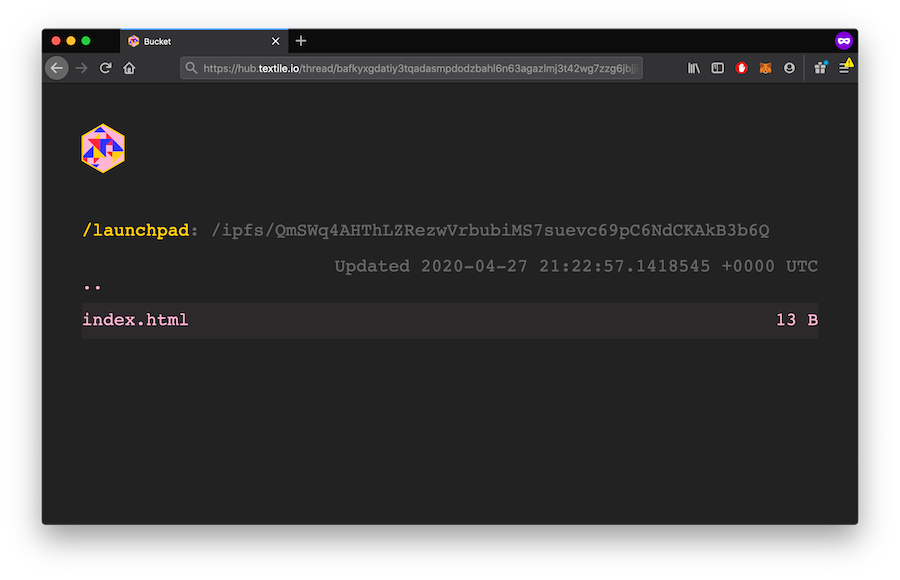
The Hub gateway gives you a static URL where you can explore, download, and share your latest Bucket content.
Render on a website¶
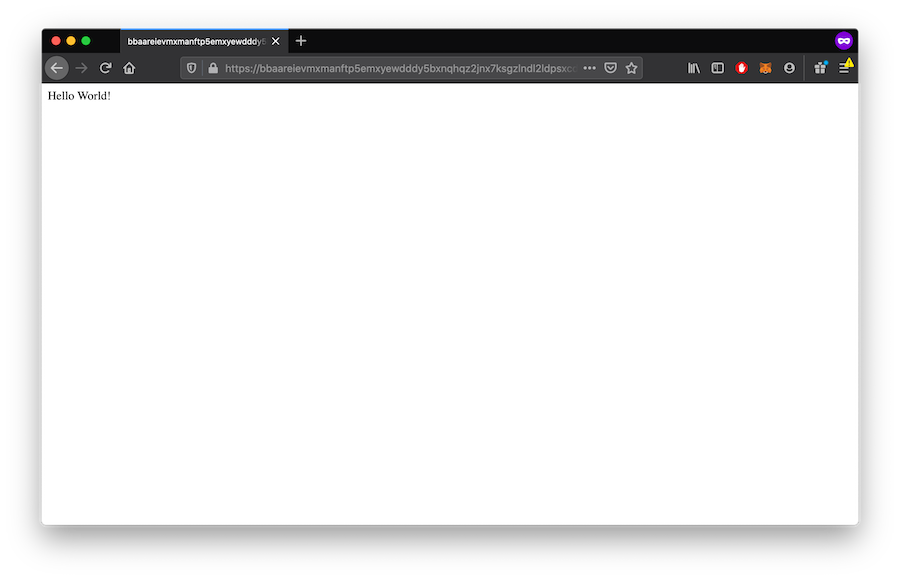
If your Bucket contains web content, the Bucket website endpoint will provide you a static URL that'll always render the latest content from your Bucket. See HTTP Domains.
Render on IPFS gateways¶
Buckets are dynamic folders distributed over IPFS using ThreadDB.
Each time you create a new Bucket, you'll receive a new IPNS Address that you can use on the IPFS address to fetch the latest Bucket content.
The IPNS address will not change but the content will update each time you push changes to your Bucket.
Each time you update your Bucket, you'll receive a new IPFS address to fetch that version of your Bucket content.
HTTP Domain¶
All public Buckets are automatically provided a subdomain on textile.space that reflects the latest changes in your Bucket.
Your Bucket's IPNS address is used as the subdomain, such that your Bucket URL will always be: <ipns-address>.textile.space.
This is designed to enhance the interoperability of protocols using Textile Buckets.
IPNS Address¶
Each Bucket has a unique IPNS address that allows you to render or fetch your Bucket on any IPFS peer or gateway that supports IPNS, including ipfs.io and Cloudflare.
Buckets can't change the speed of IPNS propagation through the network but we recommend you explore and try for yourself. The Hub gateway will always render the latest data right away.
Bucket Automation (CI/CD)¶
Buckets are an ideal tool for persisting your website, source code, or documentation on IPFS using continuous integration. Tools like Travis CI, CircleCI, and GitHub Actions make this easy.
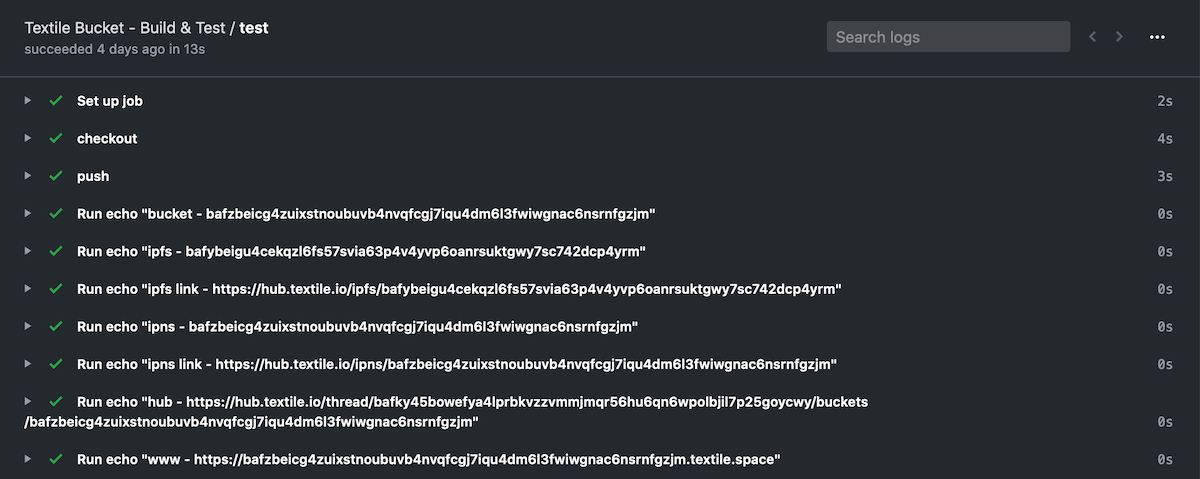
We've provided a configurable GitHub Action that allows you to:
- Push or update your Bucket based on pull requests, commits, and merges.
- Generate IPNS, IPFS, and HTTP addresses for every Bucket creation or update.
- Create temporary Buckets for staging or review that can be removed automatically when content is merged or pull requests are closed.
Cross Protocol Support¶
Buckets are designed to be interoperable across protocols and services. Here are a few examples.
Buckets and Threads¶
Buckets are built on ThreadDB. In fact, in their most basic form, Buckets are just a document in a Thread that is updated each time the directory of data is updated. Since buckets run on Threads, it opens the door to many new integrations that can be built on Buckets!
Buckets and HTTP¶
Buckets can be rendered over HTTP through either the Hub Gateway, the Bucket subdomains, or on any IPFS gateway supporting IPNS (see below).
Buckets and IPFS¶
Data in a Bucket is stored as IPLD and pinned on IPFS. You can use the underlying content addresses to pin new Bucket content on additional pinning services such as Pinata or Infura. This can be useful if you want additional replication of your content on the IPFS network.
Buckets and IPNS¶
Every Bucket you create has a unique ID associated with it. The Bucket ID is an IPNS address that you can use to fetch the latest Bucket content from any IPFS peer or view it over IPFS gateways that support the IPNS protocol.